

The growing gap between how much code exists in a system and how much of it the developer genuinely understands is comprehension debt. Unlike traditional technical debt—where teams knowingly accept shortcuts they can schedule to repay—comprehension debt accumulates invisibly, often without a single deliberate decision. And in global capability center (GCC) environments, where teams rotate every 18–24 months and institutional knowledge walks out the door on a regular cycle, the compounding effect is devastating.
This article defines comprehension debt as a distinct liability, documents why it accelerates in GCC environments, quantifies the real cost, and presents a measurement and mitigation framework that enterprise teams can implement immediately.
What Comprehension Debt Is And What It Is Not
Technical debt is code you know is bad. Comprehension debt is code you don’t understand. The distinction matters because the two demand fundamentally different responses. Technical debt announces itself through mounting friction—slow builds, tangled dependencies, failing tests. Comprehension debt breeds false confidence. The tests pass. The deployments succeed. The dashboards stay green.
Addy Osmani, engineering leader at Google, frames comprehension debt as the result of a speed asymmetry introduced by AI tools: code is now generated far faster than humans can evaluate it. In traditional environments, senior engineers reviewed code faster than juniors could write it. AI has inverted that relationship. A mid-level developer with Copilot can generate code faster than a staff engineer can audit it, creating an ever-widening gap between production and understanding.
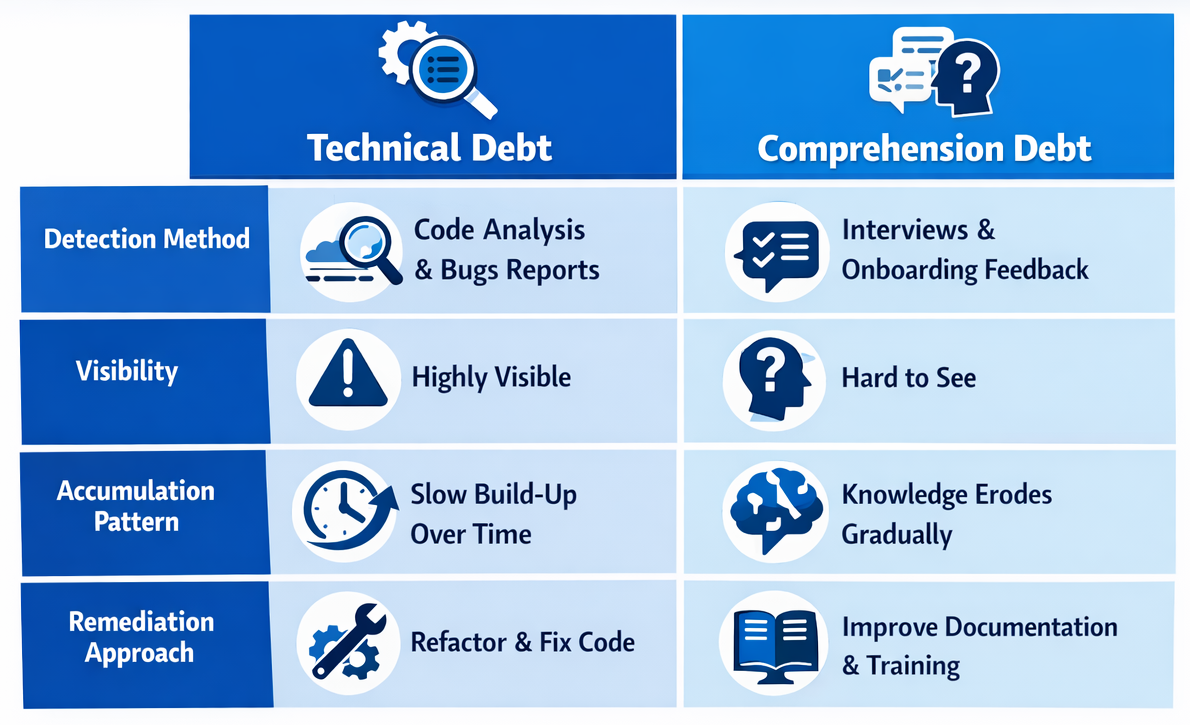
Consider the practical difference. When a team inherits technical debt, they see the tangled code, feel the friction, and can estimate the cleanup effort. When a team inherits comprehension debt, they see clean, well-formatted code that compiles—and have no idea what design decisions led to it or how different subsystems interact. The first is painful but navigable. The second is a ticking time bomb.
Why Comprehension Debt Compounds Faster in GCC Environments
Global capability centers already face structural knowledge-transfer challenges. Teams operate across time zones, cultural contexts, and organizational boundaries. Documentation is perpetually incomplete. Onboarding is extended. One in three GCCs report concerns about talent loss in early employment stages, and even best-in-class centers maintain attrition rates around 12–13%.
Now layer AI-generated code on top of those structural challenges. When a developer who used Copilot to generate a microservice’s error-handling logic rotates off the team, the replacement inherits code that no human being architected from first principles. The original developer may have understood it partially; the successor starts at zero. In a GCC rotation cycle of 18–24 months, this pattern repeats three or four times before the system reaches maturity—each rotation stripping another layer of institutional understanding.
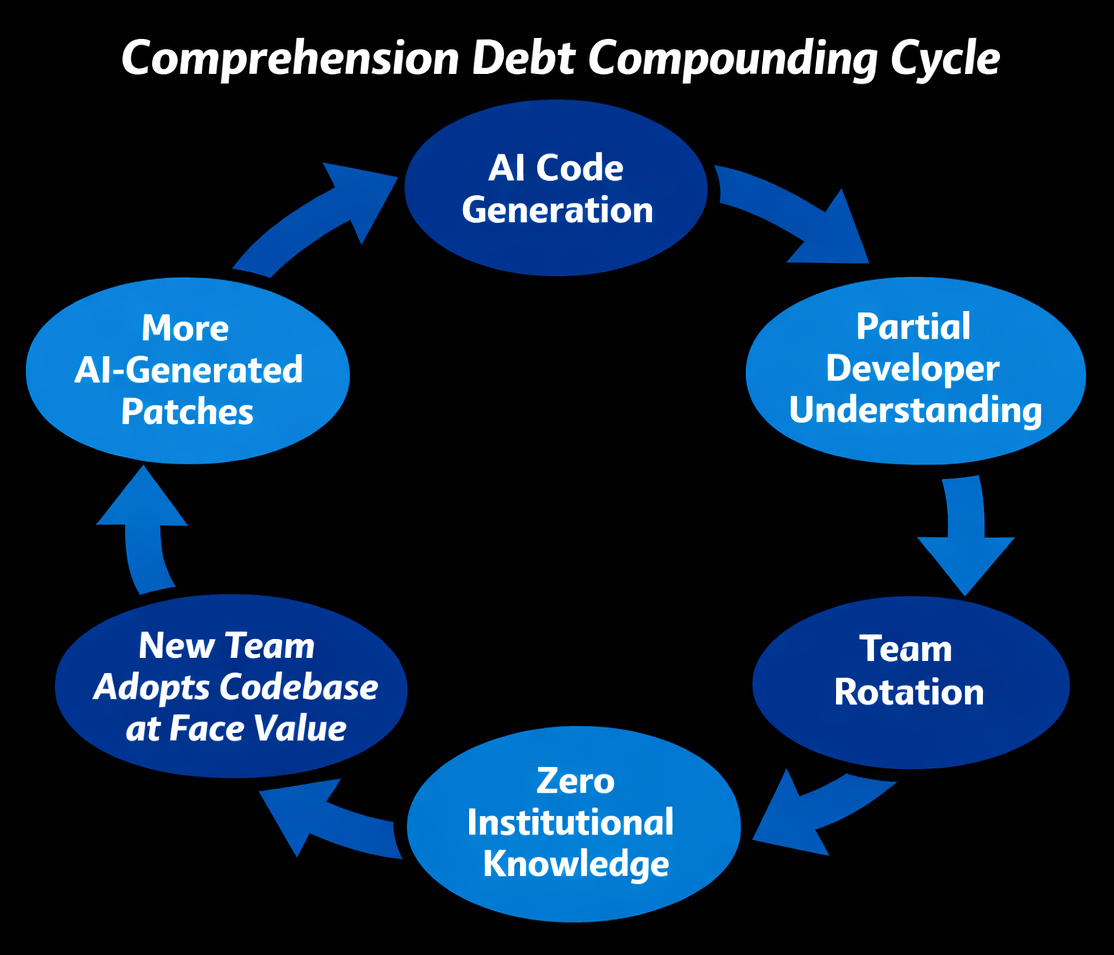
The Documentation Illusion
Some organizations believe documentation solves the problem. It doesn’t—at least not at the level that matters. AI-generated code often has plausible-looking comments (also AI-generated) that describe what the code does without capturing why specific approaches were chosen. The critical decisions—why this concurrency model over that one, why this error boundary exists—are never recorded because no human made those decisions consciously.
The Real Cost: Fixing AI-Induced Bugs Takes Longer Than Writing From Scratch
The productivity narrative around AI coding tools is fracturing under empirical scrutiny. A METR study of experienced open-source developers found that developers using AI tools for real-world maintenance tasks took 19% longer than those working without them—despite perceiving themselves as 20% faster. That 39-point perception gap is itself a symptom of comprehension debt: teams believe they are moving faster precisely because they don’t understand the complexity they are introducing.
Anthropic’s own randomized controlled trial with 52 software engineers found that AI-assisted participants scored 17% lower on comprehension assessments (50% vs. 67%), with the steepest declines in debugging ability. The pattern is consistent: developers who delegated code generation to AI without asking conceptual questions scored below 40% on comprehension tests. Those who used AI for inquiry—asking questions, exploring tradeoffs—scored above 65%.
GitClear’s analysis of over 100 million lines of changed code quantifies the downstream impact: code churn—lines reverted or rewritten within two weeks—increased by 39% in AI-heavy projects. Ox Security’s review of 300+ repositories identified ten recurring anti-patterns in 80–100% of AI-generated code, including incomplete error handling, weak concurrency management, and inconsistent architectural patterns.
The aggregate picture is stark. While AI tools increase delivered code volume by 30–40%, net productivity gains after rework settle around 15–20%, according to Stanford research. For enterprise systems with long maintenance horizons, the math often turns negative by year two.
Measuring Comprehension Debt: A Practical Framework
Current engineering metrics—velocity, DORA metrics, code coverage, PR throughput—cannot capture comprehension deficits. Nothing in the standard measurement toolkit distinguishes between a developer who wrote a function from first principles and one who accepted an AI suggestion without fully understanding it. Building a comprehension debt measurement system requires tracking three dimensions.
Dimension 1: Code Provenance Tracking
Tag every code contribution by its generation method: human-authored, AI-assisted with human review, or AI-generated with minimal modification. This metadata doesn’t judge quality—it creates the audit trail necessary for targeted comprehension assessments. Without provenance data, you’re measuring a blind spot.
Dimension 2: Comprehension Assessments
Periodically assess whether the team maintaining a module can explain its design decisions, error boundaries, and failure modes without consulting the code directly. These aren’t examinations—they’re structured walkthroughs during sprint retrospectives or architecture reviews. Track the comprehension measure index (CMI) over time and flag modules where scores decline between rotation cycles.
Dimension 3: Churn and Incident Correlation
Correlate code churn rates and incident frequency with code provenance data. If AI-generated modules show disproportionately higher churn or incident rates, comprehension debt is likely the root cause. This data-driven approach replaces gut feelings with actionable intelligence.
Mitigating Comprehension Debt: Five Practices That Work
- Mandate ‘explain before merge’ policies. No AI-generated code merges without the submitting developer recording a brief explanation of the design rationale—not what the code does, but why this approach was chosen over alternatives.
- Use AI for inquiry, not just generation. Train developers to use AI tools for conceptual exploration—asking “why would I choose approach A over B?”—rather than pure code generation. Anthropic’s research shows this single behavioral shift raises comprehension scores from below 40% to above 65%.
- Implement rotation-aware knowledge transfer. Before every GCC team rotation, conduct structured handoff sessions focused specifically on AI-generated modules. Require outgoing developers to walk successors through the decision rationale, not just the system architecture.
- Establish comprehension debt budgets. Just as teams budget for technical debt remediation, allocate sprint capacity for comprehension debt reduction—dedicated time for teams to study, refactor for understanding, and document the ‘why’ behind critical modules.
- Deploy deterministic verification layers. Tests, static analysis, and linters verify behavior but not understanding. Pair them with architecture decision records (ADRs) and design review gates to create a dual verification system that catches both code defects and comprehension gaps.
Conclusion
Comprehension debt is not a future risk—it is an existing liability hiding behind passing test suites and green dashboards in every enterprise that has adopted AI coding tools. The organizations that treat understanding as a measurable, manageable asset—rather than an assumed byproduct of code review—will maintain the ability to debug, extend, and trust their systems as AI-generated code volumes accelerate.
Start by tagging code provenance this quarter and running your first comprehension assessment during the next sprint retrospective. For teams navigating the intersection of AI adoption and GCC operations, Crewscale helps organizations build the expertise frameworks that keep human understanding ahead of machine output. The enterprises that invest in comprehension now will be the ones still capable of shipping with confidence in the coming years.








