

Every engineering team today version-controls its application code. Most version-control their infrastructure, too, thanks to the infrastructure-as-code revolution that Terraform and Pulumi popularized over the past decade. Yet when it comes to the contextual knowledge that powers an organization’s AI systems—the prompts, domain rules, architectural conventions, retrieval configurations, and guardrails—most teams still treat these assets as afterthoughts: scattered across chat logs, wiki pages, and one-off configuration files that nobody owns and nobody reviews.
That gap is becoming untenable. As context engineering replaces simple prompt engineering as the critical discipline of 2026, organizations need a systematic way to author, test, version, and deploy the knowledge that shapes how AI agents behave. The answer is a paradigm we call Context as Code: applying the same rigor that DevOps brought to infrastructure—version control, peer review, automated testing, registries, and governance—to an organization’s AI knowledge base.
This article explores what Context as Code looks like in practice, why it matters for enterprise AI, and how to build the pipelines and governance structures that turn ephemeral AI context into a durable, auditable, continuously improving asset.
From Prompts to Context Artifacts
In 2024, the state of the art in AI configuration was a single prompt string passed to a model endpoint. Today, the scope of what qualifies as “context” has expanded dramatically. Modern AI agents consume structured knowledge artifacts that include system prompts and behavioral instructions, domain-specific rules and conventions, retrieval-augmented generation (RAG) configurations, tool definitions and access policies, guardrails and safety constraints, and organizational memory—past decisions, architectural rationale, and known failure modes.
This expansion is well-documented in the research. A recent arXiv study on codified context infrastructure describes a three-component system developed during the construction of a 108,000-line distributed system: a hot-memory constitution encoding conventions and orchestration protocols, 19 specialized domain-expert agents, and a cold-memory knowledge base of 34 on-demand specification documents. The insight is that what matters is not general domain expertise but project-specific conventions, architectural decisions, and known failure modes—context that only the organization itself can supply.
When context grows this rich and this consequential, treating it as an unmanaged, ad-hoc artifact is the equivalent of deploying production infrastructure by SSH-ing into servers and editing configuration files by hand. The infrastructure-as-code movement solved that problem a decade ago. Context as Code applies the same logic: if it shapes system behavior, it should be versioned, reviewed, tested, and deployed through a pipeline.
The Emerging Ecosystem of AI Configuration Files
The open-source community has already begun formalizing context artifacts. A wave of AI configuration files now lives at the root of software repositories, providing persistent, machine-readable instructions to AI coding agents. CLAUDE.md gives Claude Code project-level memory. AGENTS.md serves as a cross-tool standard recognized by Claude Code, Cursor, GitHub Copilot, Gemini CLI, Windsurf, and a growing roster of editors. Copilot-instructions.md, .cursorrules, and GEMINI.md serve similar roles for their respective platforms.
What unites these files is a shared design philosophy: context should be declarative, colocated with the codebase, and version-controlled alongside it. As research on context engineering for AI agents in open-source software observes, the lack of prompt management limits reproducibility. Making prompt and context information explicit and manageable through versioned configuration files is a prerequisite for reliable AI-assisted workflows.
Google’s open-source Conductor extension for Gemini CLI pushes the pattern further. Conductor stores product knowledge, technical decisions, and work plans as versioned Markdown inside the repository, then drives AI agents from those files instead of ad-hoc chat prompts. The result is AI behavior that is repeatable across machines, shells, and team members—a fundamental requirement for enterprise adoption.
Applying Infrastructure-as-Code Principles to AI Context
The infrastructure-as-code movement succeeded because it codified four principles: declarative definitions, version control, automated provisioning, and policy enforcement. Context as Code maps each principle to the AI knowledge domain.
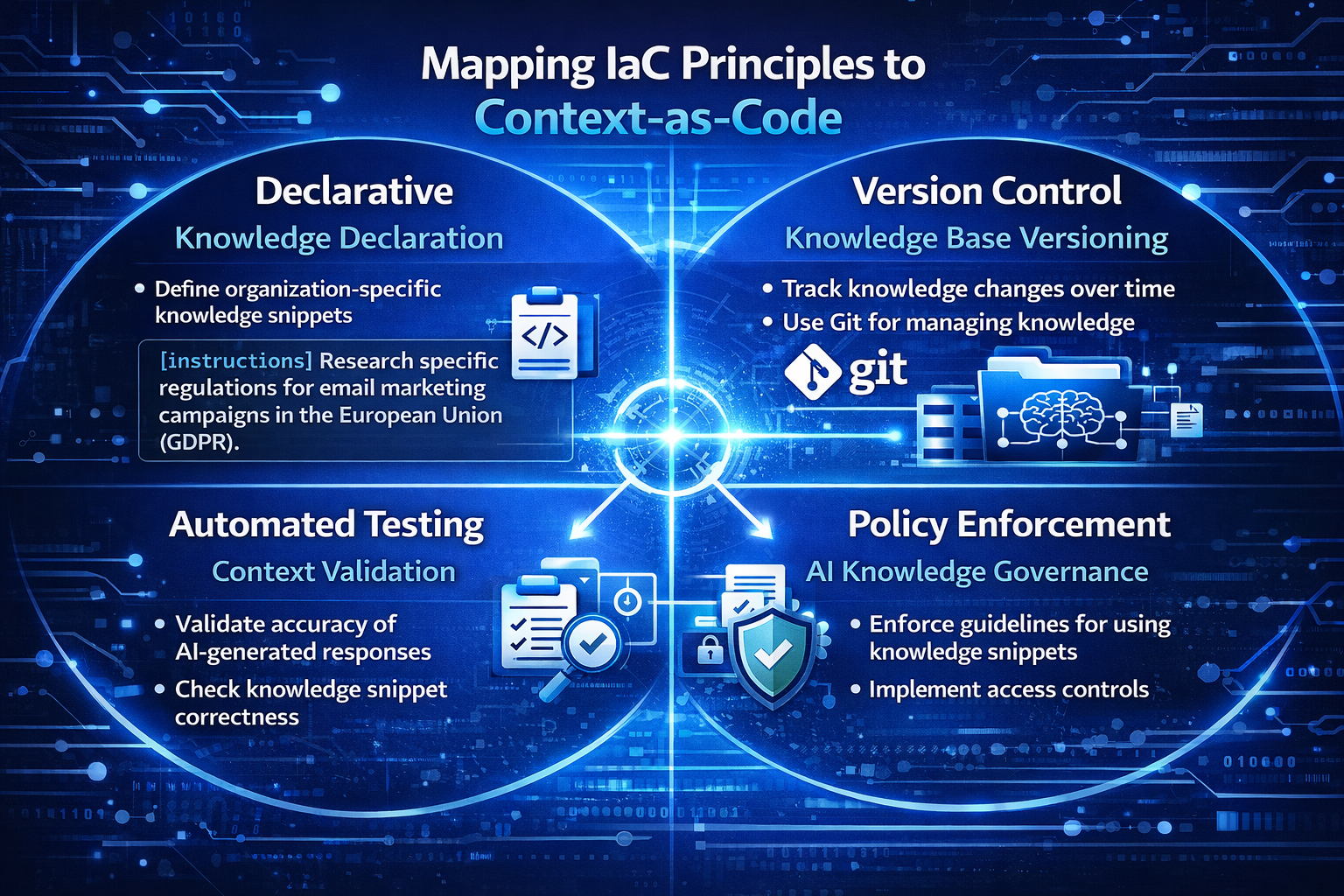
Declarative Definitions
Just as a Terraform file declares the desired state of cloud resources, a context artifact declares the desired knowledge state of an AI agent. The artifact specifies what the agent should know (domain rules, conventions), how it should behave (guardrails, tone), and what tools it can access—without prescribing the execution path. This separation of intent from implementation allows the same context to be consumed by different models, versions, or orchestration frameworks.
Version Control and Peer Review
Storing context artifacts in Git unlocks the entire pull-request workflow: diff visibility, code review, blame history, and branch-based experimentation. When a product manager updates a guardrail or an engineer modifies a retrieval strategy, the change is visible, attributable, and reversible. Knowledge management practitioners emphasize that organizations should archive configurations and interactions with the same discipline they apply to policies and procedures, enabling historical analyses and audits to be grounded in context.
Automated Testing
Infrastructure-as-code pipelines run plan and validate steps before applying changes. Context pipelines can do the same. Automated tests can verify that a context update does not introduce contradictions between instructions, that retrieval configurations return relevant documents for a benchmark set of queries, that guardrails correctly block prohibited outputs, and that agent behavior on a curated evaluation suite remains within acceptable bounds. These tests become the safety net that makes frequent iteration possible without regressions.
Policy Enforcement and Governance
Just as Open Policy Agent (OPA) enforces compliance rules on infrastructure deployments, context governance layers can enforce organizational rules on AI knowledge artifacts. Policy-as-code approaches are already being extended to AI systems, where policies are treated as living assets—continuously generated, validated, enforced, and evolved—spanning security, compliance, cost management, and operational best practices. In an AI-first enterprise, every context change that touches customer-facing behavior might require sign-off from legal and compliance, just as infrastructure changes in regulated industries require security review.
Context Registries: The Package Manager for AI Knowledge
Infrastructure-as-code ecosystems rely on registries—Terraform Registry, Helm Hub, Docker Hub—to share, version, and distribute reusable modules. Context as Code demands an analogous construct: the context registry.
A context registry is a centralized (or federated) store where teams publish versioned context packages—collections of prompts, domain rules, retrieval configurations, tool definitions, and evaluation suites—that other teams can discover, depend on, and compose into their own agents. Think of it as npm or PyPI, but for organizational knowledge artifacts.
The mechanics are familiar to any developer: semantic versioning (v1.2.3) communicates the scope of changes. A lock file pins the exact context version consumed by a production agent, preventing configuration drift. Dependency resolution ensures that when the compliance team updates a guardrail package, all downstream agents pull the new version on their next deployment cycle.
Early implementations of this pattern are already visible. Google’s Vertex AI Prompt Registry provides a management layer for prompts that treats them as versioned, testable, deployable assets. Pulumi’s infrastructure platform integrates infrastructure-as-code with policy governance and AI, providing a unified context graph that agents can query. These platforms signal the direction: AI knowledge artifacts will be managed with the same tooling rigor as software packages.
Building the Governance Layer
Governance is the dimension where Context as Code diverges most from traditional infrastructure-as-code. Infrastructure changes have well-understood blast radii: a misconfigured load balancer takes down a service. AI context changes have epistemic blast radii: a subtle guardrail modification can alter how an AI agent advises thousands of customers, with consequences that are harder to predict and slower to detect.
Effective context governance requires several components working together. An ownership model defines who can author, review, and approve changes to different context domains. The compliance team owns guardrail packages. The product team owns user-facing behavioral instructions. The engineering team owns tool definitions and retrieval configurations. Cross-cutting changes require multi-party review, similar to CODEOWNERS files in GitHub.
An audit trail records every context change, who made it, who approved it, and what evaluation results looked like before and after. In regulated industries, AI responses must be traceable, explainable, and auditable—knowledge bases that provide version control, approval workflows, and audit trails are a compliance prerequisite, not a luxury.
A rollback mechanism allows instant reversion to a prior context version when an update produces unintended behavior. Because context artifacts are versioned in Git, rollback is as simple as reverting a commit—but the surrounding tooling must support rapid redeployment of the previous context state to all consuming agents.
Lifecycle management ensures context artifacts are treated as living assets, not write-once documents. AI governance frameworks emphasize that prompts, context configurations, and fine-tuning data should have planned update cycles, deprecation paths, and active stewardship—just like software libraries.
The Context CI/CD Pipeline in Practice
Bringing these ideas together yields a deployment pipeline for AI context that mirrors a standard software CI/CD workflow, adapted for the unique characteristics of knowledge artifacts.
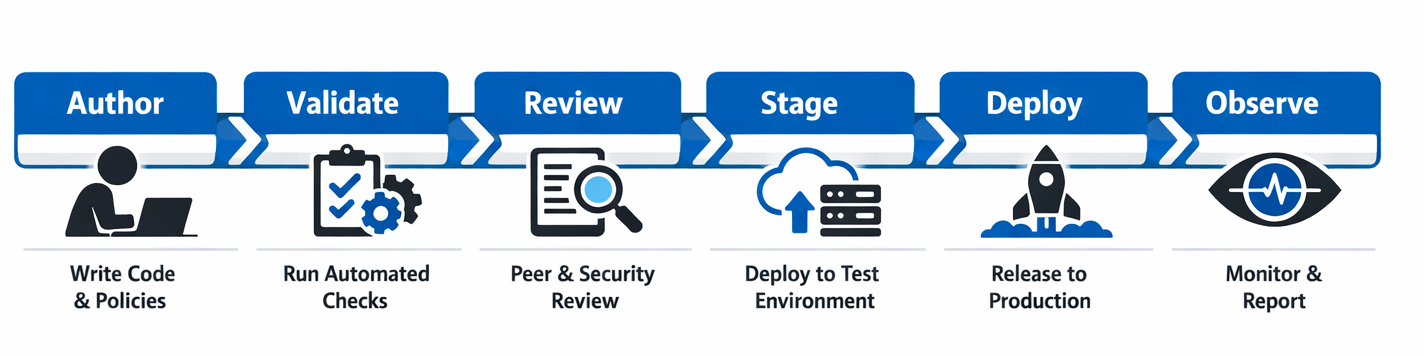
Stage 1: Author
An engineer, product manager, or domain expert modifies a context artifact in a feature branch. The artifact might be a Markdown file defining agent behavior, a YAML file configuring retrieval parameters, or a JSON schema specifying tool access policies.
Stage 2: Validate
A CI pipeline runs automated checks: schema validation ensures the artifact conforms to the expected structure. Contradiction detection flags rules that conflict with the existing context. Evaluation suites run the updated context against benchmark queries and compare outputs to expected baselines.
Stage 3: Review
The pull request enters peer review, where designated context owners examine the change, assess its intent, and evaluate its test results. For changes touching customer-facing behavior or compliance boundaries, additional reviewers from legal or compliance are required.
Stage 4: Stage
The merged context is deployed to a staging environment where shadow testing runs the new context alongside the production context, comparing outputs for divergence. This canary approach catches regressions that automated tests might miss.
Stage 5: Deploy
The context package is published to the registry with a new semantic version tag and rolled out to production agents. Monitoring dashboards track key behavioral metrics—response quality scores, guardrail activation rates, user satisfaction signals—to surface issues early.
Stage 6: Observe
Post-deployment observability feeds back into the next iteration. Drift detection compares live agent behavior against the declared context state, flagging divergence. Usage analytics reveal which context components are most accessed, least effective, or potentially redundant.
Why This Matters Now
Three converging trends make Context as Code urgent in 2026.
- Agentic AI is going mainstream.
AI agents that autonomously plan, execute multi-step tasks, and interact with external systems are moving from research demos to production deployments. These agents are only as reliable as the context that guides them. The Git-ContextController framework demonstrated that structured context management improved autonomous task resolution from 11.7% to 40.7%—a threefold improvement that underscores how much performance hinges on context quality.
- Regulatory pressure is mounting.
AI governance regulations increasingly require organizations to demonstrate traceability and auditability of AI decision-making. Version-controlled context artifacts provide a natural compliance surface: regulators can inspect exactly what knowledge an agent possessed at any point in time, how that knowledge changed, and who approved the changes.
- Organizational knowledge is becoming a competitive moat.
As foundation models commoditize, the differentiator shifts to proprietary context—the domain knowledge, customer understanding, and operational wisdom that an organization encodes into its AI systems. Companies that manage this asset with discipline will build compounding advantages over those that leave it scattered and ungoverned.
Conclusion
Context as Code is not a distant aspiration—the building blocks exist today. Version control, configuration files like AGENTS.md and CLAUDE.md, prompt registries, policy-as-code engines, and evaluation frameworks all provide the foundation. What’s needed is the organizational commitment to treat the AI context with the same engineering discipline that transformed infrastructure management a decade ago.
Start by auditing your organization’s current AI context: where does it live, who maintains it, and how are changes tracked? Then begin the migration—move context into version control, establish ownership and review processes, build automated validation, and stand up a registry for reusable knowledge packages. The organizations that codify their AI knowledge base today will be the ones whose agents are most reliable, compliant, and capable tomorrow.








