

India’s Global Capability Centres are at an inflection point. With over 1,800 centres employing 2 million people and generating $64.6 billion in annual revenue, these offshore hubs have outgrown their back-office origins. Today, 58% of GCCs are investing in agentic AI, and more than 80% are scaling generative AI from pilots into production. The architectural decisions they make now about their data and knowledge layers will determine whether their AI initiatives deliver real enterprise value or stall at proof-of-concept.
At the heart of that architectural decision sits a choice that most technology leaders are only beginning to grapple with: should your AI stack be anchored by a knowledge graph—a structured semantic map of entities and relationships—or a context graph—a dynamic, runtime layer that captures not just what your organization knows, but how and why it makes decisions? The distinction is not academic. It shapes everything from how your AI agents reason to whether your compliance posture holds up under regulatory scrutiny.
Understanding the Two Architectures
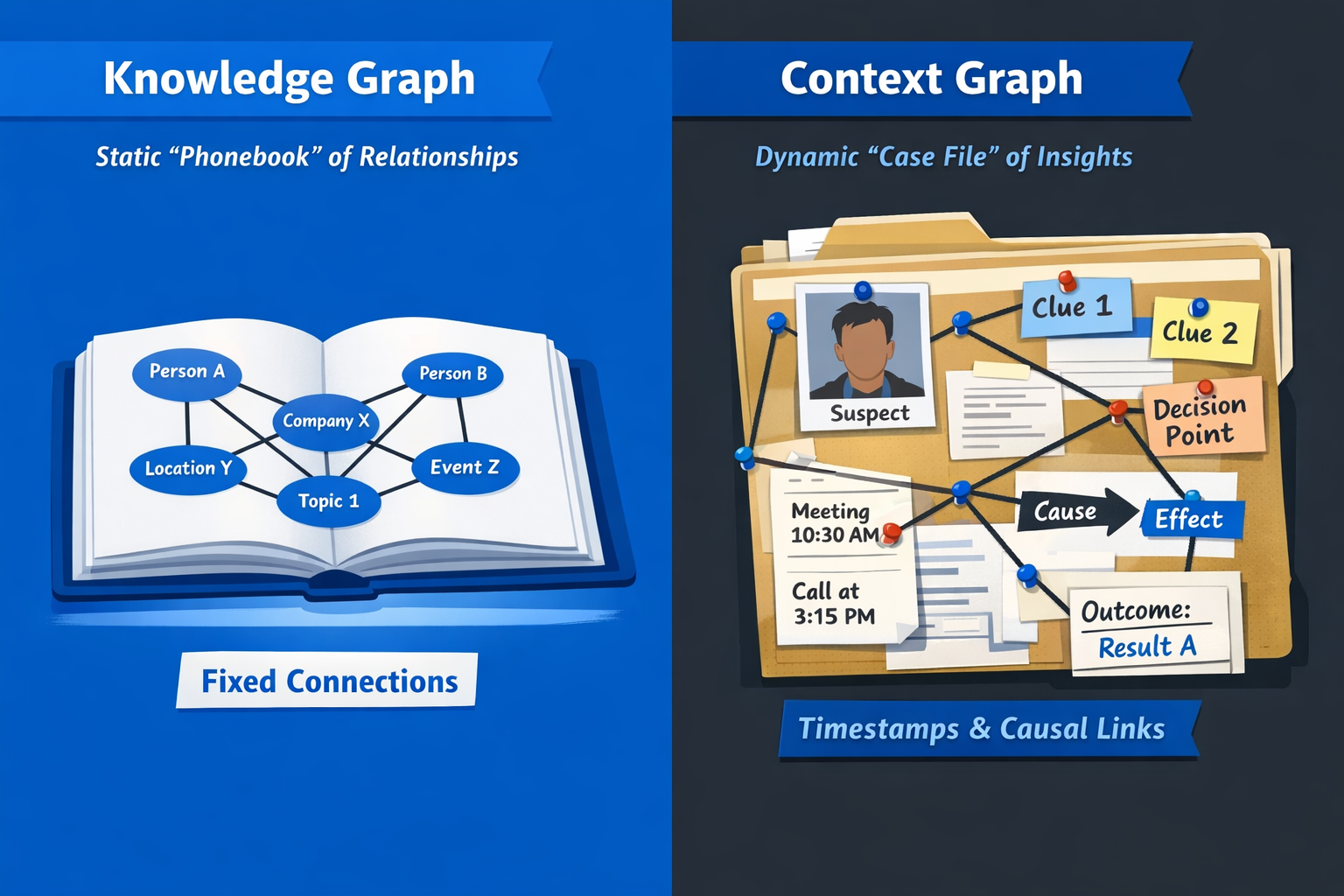
Knowledge Graphs: The Structured Semantic Foundation
A knowledge graph encodes entities (nodes) and relationships (edges) into a semantic network of verified facts. Think of it as your enterprise’s structured memory: it knows that Customer A purchased Product B from Vendor C, that the purchase order was approved by Manager D, and that Product B belongs to Category E. The graph organizes these relationships as subject-predicate-object triples, enabling multi-hop queries, semantic search, and deterministic reasoning.
Knowledge graphs have become a foundational layer in modern AI stacks, particularly as enterprises adopt Retrieval-Augmented Generation (RAG) architectures. By grounding large language models in factual, structured data, they reduce hallucination, enable accurate retrieval, and impose degrees of determinism on inherently probabilistic models. For GCCs handling shared services, IT operations, and analytics across geographies, knowledge graphs provide a single source of truth that multiple AI applications can query.
Context Graphs: The Decision-Aware Runtime Layer
Context graphs extend the knowledge graph paradigm by adding a critical dimension: operational and decision-making context. While a knowledge graph records what exists, a context graph captures why a decision was made, who made it, under what constraints, and what happened as a result. Technically, this is often implemented through quadruples or n-tuples that layer provenance, temporal validity, authorization metadata, and exception logic on top of standard triples.
Enterprises have systems of record for customers, employees, and transactions, but they have no system of record for how decisions get made. Context graphs fill that gap by persisting decision traces—the inputs, evaluations, approvals, and outcomes that form the reasoning chain behind every consequential business action. Over time, these traces accumulate into a living, queryable record of institutional decision-making.
Side-by-Side Comparison
The following table distills the core architectural differences between the two approaches across the dimensions that matter most to GCC technology leaders.
The Context Gap: Why Knowledge Graphs Alone Fall Short
The argument for context graphs is rooted in a specific enterprise failure mode. Analyst Sanjeev Mohan has observed that while knowledge graphs can traverse traditional transactional data—who bought what and when—they typically miss the reasoning that lives outside transaction systems: in email threads, Slack conversations, web searches, support interactions, and approval workflows. That missing context is precisely what AI agents need to make enterprise-grade autonomous decisions.
Consider a practical GCC scenario: a shared services team processes thousands of vendor payment approvals monthly. A knowledge graph tells you that Invoice X from Vendor Y was approved by Manager Z. But it cannot tell you that Manager Z approved it despite a flagged discrepancy because an exception clause in the procurement policy permitted deviations below a certain threshold, and that the decision was informed by a conversation with the vendor’s account manager documented in a support ticket. A context graph captures that entire decision chain, making it auditable, searchable, and reusable as precedent for future AI-assisted approvals.
This distinction becomes especially important as GCCs move into agentic AI territory. An AI agent operating autonomously needs more than factual grounding—it needs to understand organizational norms, exception logic, and the reasoning patterns that define how decisions should be made in specific contexts. Without that layer, agents either over-escalate to human reviewers (destroying the efficiency gains) or make decisions without adequate governance (creating compliance risk).
The Skeptic’s Case: Why Context Graphs Are Not a Silver Bullet
Not everyone is convinced that context graphs represent a fundamentally new paradigm. Industry analysts have noted that the core challenges of data integration, ontology alignment, and governance do not disappear simply by adding a contextual dimension—they become more complex. The cost and instrumentation burden of capturing decision traces at runtime is significant, and most implementations remain confined to pilot projects.
Critics also raise a deeper architectural concern that context graphs rely on a dangerous assumption: that historical decision traces can reliably serve as the basis for future decisions. This "decision archaeology" approach infers rules from past behavior rather than explicitly defining decision logic through frameworks like Decision Model and Notation (DMN). In regulated industries—banking, insurance, healthcare—where GCCs frequently operate, the distinction between descriptive patterns and prescriptive policy is not merely academic; it has legal and regulatory consequences.
There is also the maturity question. True context graph implementations remain immature, with a small set of vendors—including Neo4j, Precisely, and TigerGraph—exploring context-rich approaches alongside open-source projects like TrustGraph. Industry watchers predict that many companies will claim to have context graphs in 2026, but meaningful adoption will lag well behind the marketing.
A Decision Framework for GCC Technology Leaders
Choosing between a knowledge graph, a context graph, or a layered approach combining both is not a binary decision. The right architecture depends on where your GCC sits on the AI maturity curve, the nature of the workflows you are automating, and your regulatory environment. The framework below provides a structured approach to making that determination.
Step 1: Assess Your AI Maturity Stage
Your GCC’s current AI maturity should anchor the architecture decision. Organizations at different stages need fundamentally different graph capabilities.
Step 2: Map Your Workflow Complexity
Different workflow types demand different architectural approaches. The complexity of decision-making in your target workflows is the single strongest predictor of whether you need context graph capabilities.
- Lookup-dominant workflows (entity resolution, data retrieval, semantic search): Knowledge graph is sufficient. Most shared services, IT operations, and basic analytics workloads fall here.
- Rule-governed workflows (approvals, compliance checks, policy enforcement): Consider a hybrid approach with explicit decision models (DMN/BPMN) for prescriptive logic and a knowledge graph for factual grounding.
- Judgment-intensive workflows (exception handling, risk assessment, vendor negotiations): Context graphs deliver the most value here, where decisions depend on precedent, institutional knowledge, and cross-system context that resists codification into deterministic rules.
Step 3: Evaluate Your Regulatory Exposure
GCCs operating in regulated verticals—financial services, healthcare, insurance—face a paradox. Context graphs offer superior auditability by capturing complete decision chains, but the immaturity of context graph tooling means that relying solely on this architecture introduces implementation risk. The pragmatic approach for regulated GCCs is to build a robust knowledge graph foundation with explicit decision model integration, while instrumenting high-value workflows to capture decision traces that can feed a context graph layer as the technology matures.
Step 4: Plan Your Build Path
Rather than framing this as an either/or decision, the most effective GCC architecture follows a layered progression:
- Foundation layer: Deploy a knowledge graph to unify entity definitions, relationships, and metadata across your GCC’s systems. This provides the structured substrate that both RAG applications and future context graph layers depend on.
- Instrumentation layer: Begin capturing decision traces in your highest-value, most complex workflows. Instrument approval chains, exception handling, and escalation paths. Store these traces with provenance metadata from day one, even before you build a full context graph query layer.
- Context layer: As decision trace volume accumulates and context graph tooling matures, stand up a context graph that connects to your knowledge graph foundation. This layer enables autonomous agents to query precedent, understand organizational norms, and operate within governance boundaries without constant human intervention.
Implementation Priorities for India-Based GCCs
India’s GCC landscape presents specific advantages and constraints that should shape your architecture choices. The EY GCC Pulse Survey 2025 reveals that two-thirds of GCCs are creating dedicated innovation teams to globalize ideas, and the most advanced centres are already influencing global product strategy. This positioning creates both an opportunity and an obligation to get the foundational architecture right.
Start with Cross-System Entity Resolution
Most GCCs operate across multiple enterprise systems—ERP, CRM, ITSM, HRMS, and domain-specific platforms. A knowledge graph that resolves entities across these systems eliminates the data fragmentation that cripples AI accuracy. This is the highest-leverage first investment, and it delivers immediate value to existing GenAI and analytics workloads.
Instrument Decision-Heavy Processes First
Identify the three to five processes where decision-making is most opaque, most consequential, and most reliant on institutional knowledge. Common candidates in Indian GCCs include vendor risk assessment, regulatory compliance workflows, incident escalation and resolution, and financial close processes. Begin capturing structured decision traces here, even if you are storing them in a simple graph database rather than a full context graph platform.
Build for Composability, Not Monoliths
The context graph tooling landscape is evolving rapidly. Avoid vendor lock-in by designing your graph layer as a composable service that sits alongside—not inside—your LLM infrastructure. Use open standards like RDF, OWL, or property graph models that can interoperate with multiple graph databases and query engines. This ensures that as the technology matures, your GCC can adopt best-of-breed solutions without re-architecting the entire stack.
Conclusion
The knowledge graph versus context graph choice is not a technology procurement decision—it is a strategic bet on how your GCC’s AI capabilities will evolve over the next three to five years. Knowledge graphs are proven, production-grade, and essential as a foundation. Context graphs promise to capture the institutional reasoning that separates true enterprise intelligence from sophisticated search.
For GCC leaders setting up or scaling operations in India, the wisest path is to build the knowledge graph foundation now, instrument for context capture immediately, and architect your systems so that context graph capabilities can be layered in as the technology and your organizational maturity warrant. Get in touch with Crewscale to set up your AI GCC in India.








