

Organizations that master context engineering achieve 94–99% AI accuracy, while those leaving context fragmented struggle at 10–20%. This gap reveals the defining challenge of enterprise AI in 2026: competitive advantage belongs not to those with the biggest models, but to those with the best architecture for delivering context to AI systems.
The enterprise context layer has emerged as the critical infrastructure sitting between raw data sources and AI applications. It encodes what data represents, how it connects, and why it matters—transforming scattered facts into actionable intelligence. Without this shared layer, enterprise AI behaves like a company full of capable employees with zero onboarding: eager, intelligent, and utterly uninformed about the business they serve.
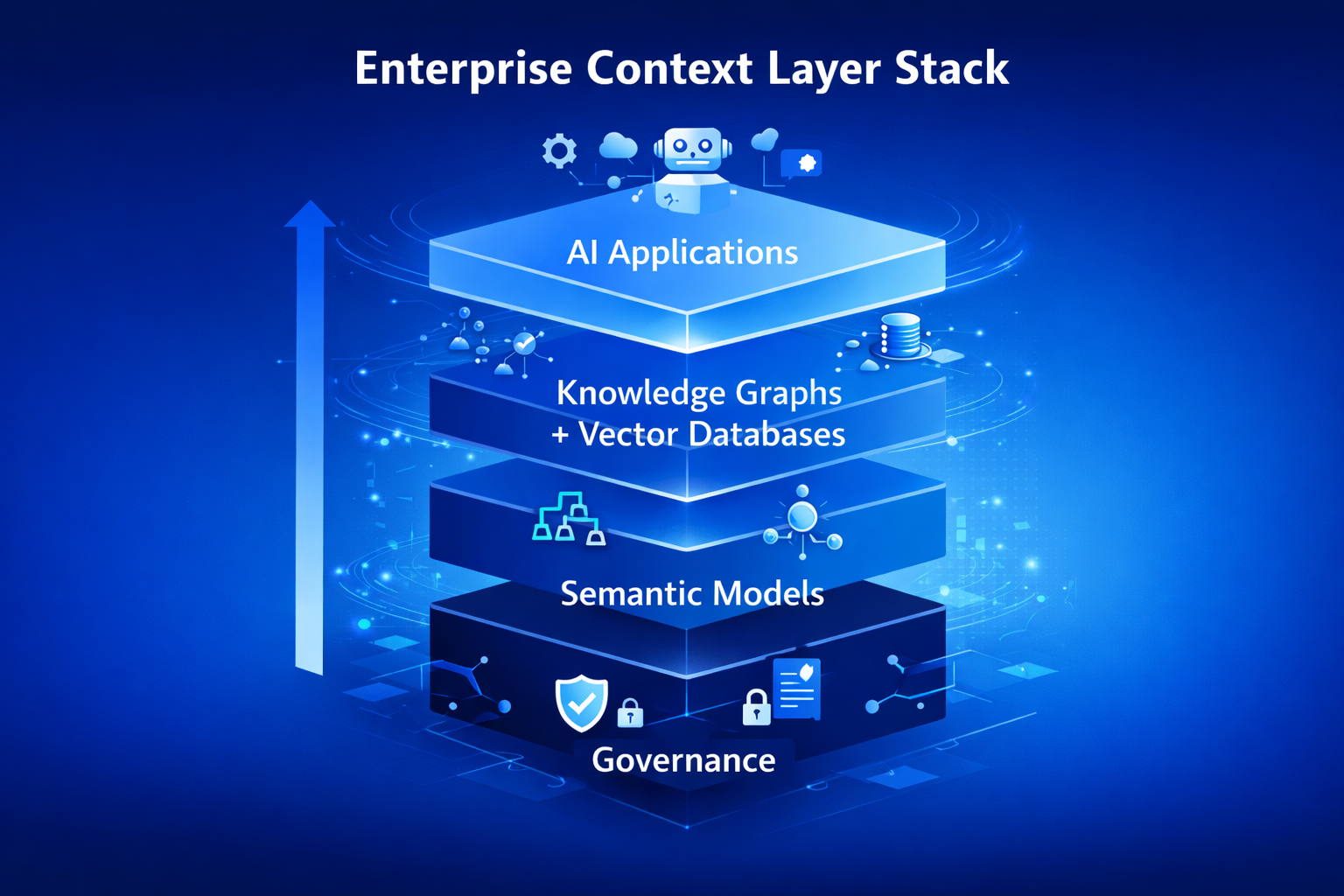
This guide breaks down the four foundational components of the enterprise context layer—knowledge graphs, vector databases, semantic models, and governance infrastructure—and shows practical integration patterns for production deployments. Whether you are building a new AI platform or retrofitting context into an existing stack, these architectural patterns provide a concrete blueprint for moving from prototype to production.
What Is the Enterprise Context Layer?
The enterprise context layer is a shared infrastructure that transforms raw data into intelligence by encoding business meaning, entity relationships, and operational rules across the organization. It sits between data systems and AI tools, making business context available to every agent, everywhere.
The need for this layer accelerated dramatically as generative AI scaled across the enterprise. Large language models lack inherent business context—they cannot distinguish between two customers with the same name, understand that “revenue” means different things in finance versus marketing, or enforce access policies on sensitive data. The old model of embedding business logic inside individual BI tools collapsed under the weight of dozens of AI applications, each needing the same foundational understanding.
The context layer solves this through four integrated components. Knowledge graphs provide structure and relationships. Vector databases enable fast semantic retrieval. Semantic models standardize business meaning. Governance infrastructure ensures trust and compliance. Together, they form a coherent stack that makes enterprise AI reliable, accurate, and auditable.
Knowledge Graphs: Structure and Relationships
Knowledge graphs form the relational backbone of the context layer, explicitly modeling business entities, their properties, and the connections between them. While vector databases answer “Find me similar content,” knowledge graphs answer “How is X related to Y?”—a distinction that becomes critical when AI systems need to reason across interconnected enterprise data.
What Knowledge Graphs Provide
- Explicit modeling of entities, relationships, and canonical identifiers across data sources
- Multi-hop reasoning that traverses connections—finding how a customer relates to a product, a regulation, and a support ticket in a single query
- Deterministic accuracy for relationship queries, complementing probabilistic vector search
Enterprise Deployment Patterns
Three patterns dominate production knowledge graph deployments in 2026. Teams map source schemas using SHACL constraints as quality gates, ensuring data entering the graph meets structural requirements. SPARQL SERVICE calls virtualize data from warehouses like Snowflake or Databricks, avoiding costly ETL pipelines. Most critically, GraphRAG pipelines wire knowledge graphs directly into LLM workflows to ground answers in verified facts.
The accuracy impact is substantial. Organizations using GraphRAG report accuracy improvements from 60% to over 90% when LLMs query knowledge graphs instead of searching unstructured document chunks alone. The graph provides the structured context that prevents hallucination and enables precise, multi-step reasoning.
Technology Choices
Vector Databases: Semantic Retrieval at Scale
Vector databases provide the semantic search engine within the context layer, enabling AI systems to find conceptually relevant content across massive unstructured datasets. They convert documents, passages, and data records into high-dimensional embeddings, then perform fast similarity searches that capture meaning rather than relying on exact keyword matches.
What Vector Databases Provide
- Embedding-based retrieval that finds semantically relevant content regardless of exact phrasing
- Sub-second search performance across millions or billions of vectors
- Hybrid filtering that combines vector similarity with structured metadata constraints
The 2026 Evolution
If 2022–2025 was about adding standalone vector databases to AI stacks, 2026 marks a shift toward hybrid retrieval architectures. The winning approach combines vector retrieval to identify relevant context with long-context windows to reason across that retrieved content. This “RAG-augmented long context” pattern outperforms either approach alone on both cost and accuracy metrics across enterprise use cases. Enterprises aren’t abandoning vectors—they’re integrating them into richer, multi-component architectures.
Technology Choices
- Pinecone: Managed vector operations with built-in filtering, ideal for teams wanting minimal infrastructure overhead
- Weaviate: Native hybrid search combining vector and keyword retrieval in a single query
- Milvus: Distributed architecture designed for enterprise-scale throughput and high availability
- Qdrant: Advanced filtering and payload support for complex metadata-driven queries
Semantic Models: The Meaning Layer
Semantic models form the business logic translator within the context layer, providing standardized definitions, consistent metric calculations, and deterministic query execution. They ensure that when an AI system references “revenue,” “active customer,” or “churn rate,” every application across the enterprise uses the same definition.
How Semantic Models Work with AI
The semantic layer handles what LLMs are fundamentally bad at—complex joins, aggregation logic, and metric computation—so models can focus on what they excel at: understanding natural language intent and reasoning about analytical workflows. This separation of concerns produces dramatically more reliable outputs than asking an LLM to generate raw SQL against undocumented tables.
The Model Context Protocol (MCP) solved a critical integration challenge by creating a standardized interface that allows AI agents to query semantic definitions directly from governed models. When constraints are embedded into the data model itself, AI inherits policy boundaries automatically—governance shifts from post-execution auditing to runtime enforcement.
Governance Through Semantics
Leading organizations manage semantic models as code using CI/CD workflows. When marketing attempts to redefine “gross margin” and that definition already exists in finance, IT rejects the pull request and points to the canonical definition. This code-based governance eliminates the conflicting metric interpretations that plague most enterprise data environments.
Industry convergence is accelerating this pattern. dbt Labs open-sourced MetricFlow for standardized metric definitions, and Snowflake formalized Open Semantic Interchange (OSI) as a cross-vendor standard. The shared understanding: semantic layers must be open and portable to scale across enterprise toolchains.
Governance Infrastructure: Trust at Runtime
Governance infrastructure forms the foundation of the context layer, ensuring that every AI interaction operates within defined policy boundaries. Without it, the other three components produce fast, semantically rich, well-structured answers that may violate regulations, expose sensitive data, or lack auditability.
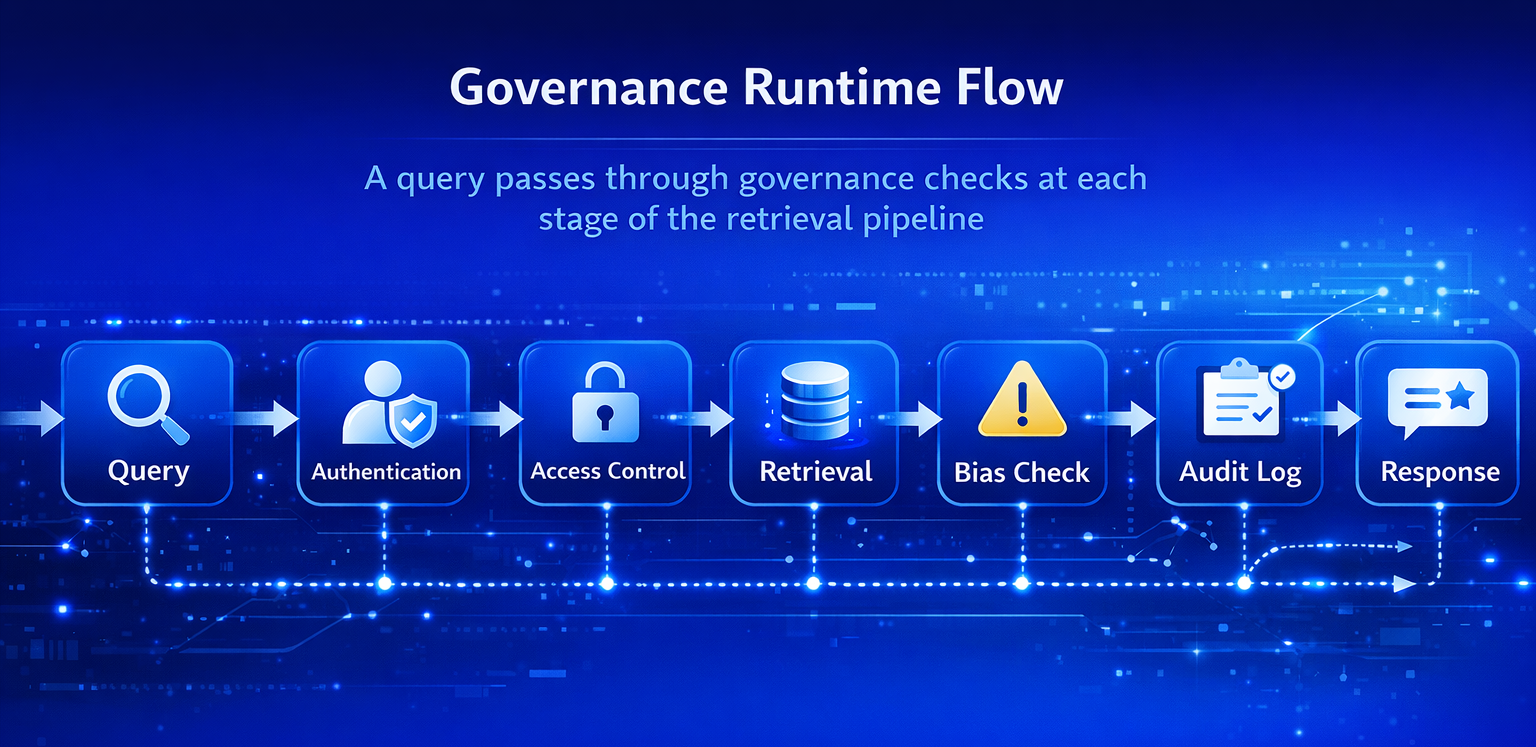
What Governance Infrastructure Provides
- Access control policies that determine which AI agents can query which data domains
- Audit trails linking every AI-generated answer to its source documents and retrieval path
- Automated bias detection in retrieval ranking and response generation
- Compliance modules that assess outputs against regulatory requirements before delivery
Runtime Enforcement vs. Post-Execution Auditing
The architectural shift in 2026 is from governance as an afterthought to governance as a runtime component. Successful deployments treat RAG as a knowledge runtime—an orchestration layer managing retrieval, verification, reasoning, access control, and audit trails as integrated operations, similar to how Kubernetes manages workloads with health checks and security policies.
This governance layer comes with real costs. The compliance infrastructure, automated documentation, audit trails, bias detection, and regulatory assessment add an estimated 20–30% to infrastructure expenses. But the alternative—deploying AI without governance guardrails—exposes organizations to regulatory penalties, reputational damage, and unreliable outputs that erode stakeholder trust.
Integration Patterns for Production Deployments
Understanding individual components is necessary but insufficient. The real architectural challenge is connecting knowledge graphs, vector databases, semantic models, and governance into coherent production pipelines. Three integration patterns have emerged as dominant approaches in enterprise deployments.
Pattern 1: Parallel Retrieval with Merged Context
In this architecture, vector and knowledge graph retrievals execute simultaneously against the same query. Vector search returns semantically similar documents while the knowledge graph returns structured relationships and entity data. Results merge at the response generation stage, giving the LLM both unstructured context and structured facts. This pattern works best for general-purpose enterprise assistants that handle diverse query types.
Pattern 2: Knowledge Graph–Guided Vector Search
This pattern uses the knowledge graph as a pre-filter. For a given query, the system first extracts key entities and relationships from the graph, then uses those entities to constrain vector search to only relevant content. A vector database might retrieve documents about all product types, but the knowledge graph ensures results are filtered to the specific product category, region, and compliance framework relevant to the query. This pattern excels in domain-specific applications requiring high precision.
Pattern 3: Semantic Layer–Orchestrated Pipeline
The most sophisticated pattern places the semantic layer as the orchestrator. Natural language queries first pass through the semantic model, which translates intent into governed metric definitions and business rules. The semantic layer then coordinates retrieval from both the knowledge graph (for relationship context) and vector database (for document retrieval), with MCP providing the interface for AI agents to access canonical definitions. This pattern is ideal for analytics and BI-adjacent AI applications where metric consistency is paramount.
Choosing the Right Pattern
Regardless of pattern, the guiding principle remains consistent: use vectors and graph constraints together. The graph technology market has grown above $5 billion by 2025, reflecting the enterprise consensus that hybrid architectures beat any single component alone.
Conclusion
The enterprise context layer is not a single product—it is an architectural discipline that unites knowledge graphs, vector databases, semantic models, and governance into coherent, production-grade infrastructure. Organizations that treat context as shared, reusable infrastructure rather than application-specific customization will capture the most value from enterprise AI deployments.
Start by mapping your current data landscape against these four components to identify the highest-impact gaps, then prioritize the component addressing your most pressing organizational pain point. For teams looking to accelerate context layer design and implementation, Crewscale helps organizations build production-grade AI infrastructure tailored to their enterprise architecture. The competitive advantage in 2026 and beyond belongs to those who master context, not just models.








