

Security scanners flag 45% of AI-generated code as containing vulnerabilities, yet AI coding agents now routinely produce thousands of lines per hour — more in a single session than most human developers write in a week. The continuous integration and continuous delivery pipelines that engineering teams have relied on for over a decade were designed for a fundamentally different reality: humans writing, reviewing, and committing code in small, deliberate batches. That assumption no longer holds.
As AI agents shift from autocomplete assistants to autonomous contributors capable of planning, coding, testing, and committing, the infrastructure that validates and deploys software must evolve in tandem. The familiar loop of lint, build, test, and deploy was never designed to interrogate whether a syntactically perfect function is logically sound, whether a dependency actually exists in a public registry, or whether a commit should be traced back to a model version rather than a human author.
This article examines why traditional CI/CD pipelines fracture under AI-scale code generation, identifies the new failure classes that emerge when machines write software, and presents an architecture for AI-aware pipelines equipped with provenance tracking, automated compliance gates, and deterministic reproducibility checks. Whether you lead a platform engineering team or set DevSecOps policy, this is the playbook for making your deployment infrastructure AI-ready.
Why Traditional CI/CD Pipelines Were Never Built for This
Conventional CI/CD systems matured during an era when a productive developer might open two or three pull requests per day, each containing a few dozen to a few hundred changed lines. Pipeline budgets — compute, queue depth, review capacity — were calibrated for that tempo. Automated test suites assumed that code changes would be incremental and contextually coherent, written by someone who understood the surrounding architecture.
Volume and Velocity Mismatch
AI coding agents fundamentally alter the equation. Enterprise teams using agentic coding tools report 16% faster cycle times on routine tasks, but the raw volume of generated code can overwhelm pipeline resources. When multiple agents work simultaneously across a monorepo — each committing, triggering builds, and queuing test runs — pipeline contention spikes. Build queues designed for 50 commits per hour suddenly face 500. Parallelism that once felt generous becomes a bottleneck.
The problem is not simply throughput. Traditional pipelines treat every commit as roughly equivalent in risk profile. A 10-line human-authored fix to a well-understood module and a 2,000-line agent-generated feature touching 14 files receive the same validation treatment. Without risk-weighted triage, high-risk AI-generated changes wait behind trivial human patches, and genuine regressions slip through while the queue drains.
The Review Bottleneck
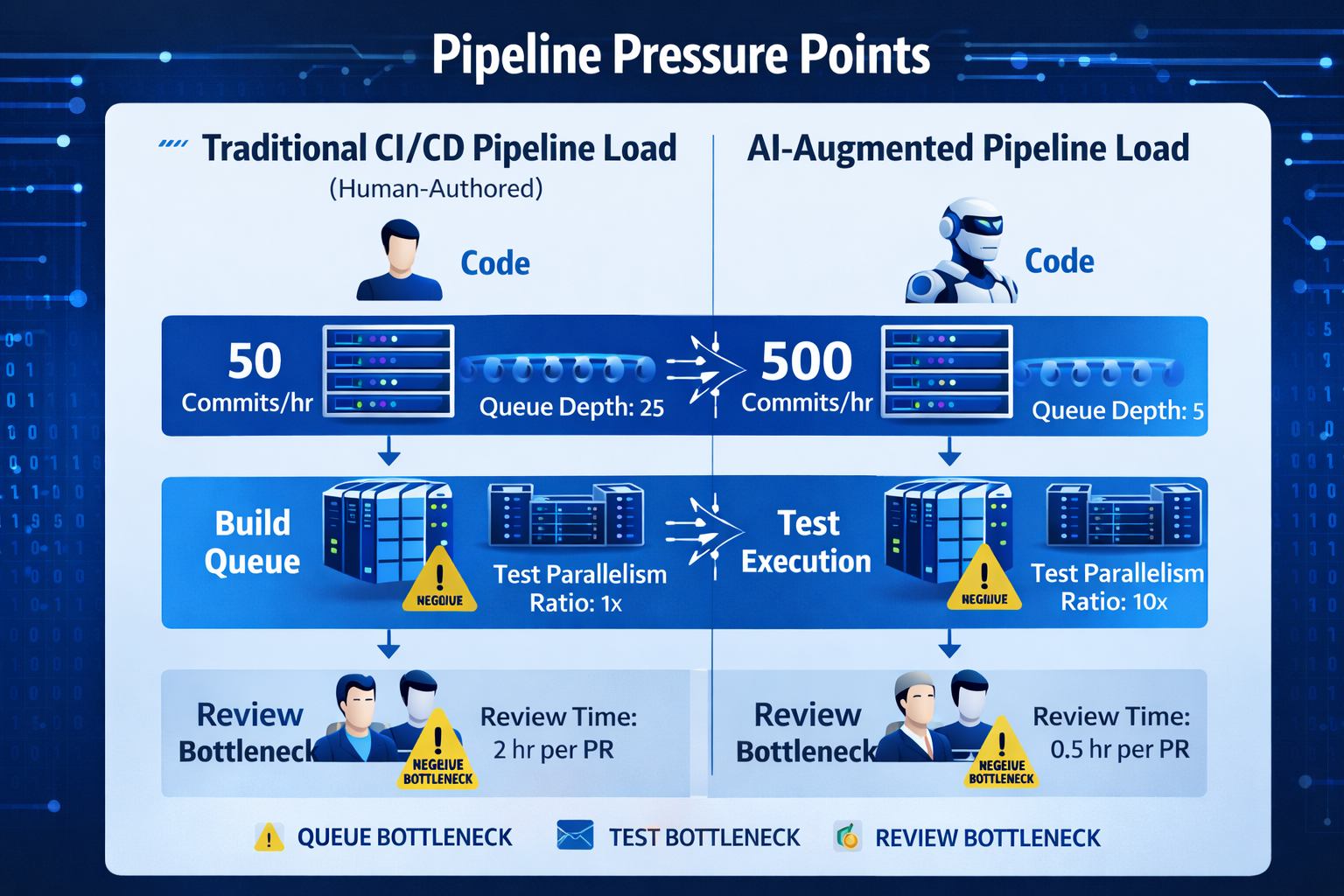
Human code review, long considered the final quality gate, becomes the constraining factor. 88% of developers already cite negative impacts from AI-generated code, including output that "looks correct but isn't reliable" and code that is "unnecessarily duplicative." Reviewing AI output demands higher expertise, not lower — the reviewer must reason about intent, verify logical correctness, and catch subtle anti-patterns that pass every linter. When code volume doubles, but reviewer headcount stays flat, the review stage becomes a dam holding back deployment velocity.
The New Failure Classes: When Correct Syntax Hides Broken Logic
AI-generated code introduces failure modes that existing CI/CD checks were never designed to detect. These are not exotic edge cases; they are systemic patterns that appear across models, languages, and frameworks.
Syntactically Correct, Logically Broken
Large language models optimize for plausibility. The code they produce compiles, passes type checks, and often reads beautifully — yet it can implement the wrong business logic entirely. An LLM asked to implement a discount calculation might produce a function that correctly applies a percentage but inverts the condition, giving discounts to ineligible customers. Static analysis tools, which look for patterns like null dereference or buffer overflow, have no framework for evaluating whether a function does what the product specification intended.
This gap is particularly dangerous because AI-generated code tends to be internally consistent. It follows naming conventions, uses appropriate data structures, and handles edge cases for the wrong problem. Unit tests written by the same agent often validate the incorrect logic, creating a closed loop of false confidence.
LLM-Introduced Security Anti-Patterns
Beyond logic errors, AI models systematically reproduce security anti-patterns from their training data. Veracode's analysis of over 100 LLMs found that common vulnerabilities include hardcoded credentials, SQL injection-prone query construction, insecure deserialization, and overly permissive CORS configurations. These are not random errors — they reflect the statistical distribution of code in training corpora, where insecure patterns appear alongside secure ones, and the model lacks the adversarial reasoning to distinguish between them.
The scale factor makes this critical. A human developer might introduce one insecure pattern per sprint; an AI agent can replicate the same anti-pattern across dozens of files in minutes, creating a systemic vulnerability surface rather than an isolated bug.
Hallucinated Dependencies: The Supply Chain Threat

Perhaps the most novel failure class is dependency hallucination. Research published by USENIX Security found that nearly 20% of packages recommended by LLMs did not exist in any public registry. These phantom packages — libraries the model "remembers" from training data patterns but that were never published — create a direct supply chain attack vector.
Attackers have already operationalized this vulnerability through a technique called slopsquatting: registering the package names that LLMs commonly hallucinate, then populating them with malicious code. Because 43% of hallucinated packages recur predictably across prompts, attackers can pre-register the most frequently invented names and wait for automated pipelines to pull them in. Traditional dependency scanning checks for known CVEs in real packages; it was never designed to question whether a package should exist in the first place.
AI-Generated Code: New Failure Classes vs. Traditional Defects
Architecture for AI-Aware Pipelines
Addressing these failure classes requires more than bolting additional scanning tools onto existing pipelines. It demands a structural rethink — a pipeline architecture designed from the ground up to treat AI-generated code as a distinct artifact class with its own validation requirements, provenance chain, and compliance obligations.
Provenance Tracking: Knowing Who — or What — Wrote the Code
The first architectural requirement is provenance. Every commit entering the pipeline must carry metadata identifying its origin: human-authored, AI-assisted, or fully AI-generated. This is not merely administrative bookkeeping — it determines which validation gates apply and what audit trail is required.
A robust provenance layer captures the model identifier and version, the prompt or task specification that triggered generation, the agent framework and configuration, any human review or modification applied post-generation, and a timestamp chain linking the generation event to the commit. The concept of an AI Bill of Materials (AI-BOM) extends the traditional Software Bill of Materials to capture these AI-specific artifacts. Just as an SBOM tracks third-party libraries, an AI-BOM tracks which model produced which code, enabling downstream auditing and incident response.
Provenance metadata should be stored as structured annotations on commits (using Git notes or trailer fields) and propagated through the pipeline as first-class context. When a production incident traces back to AI-generated code, the provenance chain allows teams to identify the model version, reproduce the generation conditions, and determine whether the same model produced similar code elsewhere in the codebase.
Automated Compliance Gates: Beyond Lint and Test
Traditional CI/CD pipelines enforce a linear sequence of gates: lint, build, unit test, integration test, and deploy. AI-aware pipelines must insert additional gates specifically calibrated for machine-generated code.
Dependency existence verification validates that every imported package actually exists in the declared registries, with a valid version history and a publication date predating the current commit. This gate catches hallucinated dependencies before they reach the build stage. Critically, it must also cross-reference against known slop squatting registries and flag any package registered within the last 90 days that matches a known LLM hallucination pattern.
Semantic logic validation goes beyond syntax checking to evaluate whether code behavior aligns with specifications. This can take the form of property-based testing generated from specification documents, contract tests that verify function inputs and outputs against documented interfaces, or differential testing that compares AI-generated implementations against reference implementations or prior behavior.
Security posture assessment applies AI-tuned static analysis that weights vulnerabilities by their likelihood of appearing in LLM output. Platforms like Sonar and Qodo now offer hybrid analysis that pairs deterministic static rules with LLM-based contextual review, catching anti-patterns that rule-based scanners miss while maintaining the reproducibility that auditors require.
Regulatory and policy gates enforce organizational policies specific to AI-generated code. With the EU AI Act's GPAI provisions now in effect and similar frameworks emerging globally, pipelines must verify that AI-generated code meets transparency and documentation requirements. This includes automated checks for licensing compliance (ensuring the generating model's training data does not create IP exposure) and jurisdiction-specific data handling rules.
AI-Aware Pipeline: Gate Architecture
Deterministic Reproducibility: Pinning the Unpinnable
Non-determinism is the defining challenge of AI-generated code in CI/CD. The same prompt fed to the same model can produce different code on successive runs. Temperature settings, context window contents, and model updates all introduce variation. This makes traditional reproducibility assumptions — that a given commit will produce the same build artifact every time — unreliable.
Deterministic reproducibility in AI-aware pipelines requires three mechanisms. First, generation pinning: capturing and versioning not just the code output but the complete generation context — model ID, prompt, temperature, system message, and any retrieval-augmented generation (RAG) context. This allows any code artifact to be re-derived from its generation inputs.
Second, artifact fingerprinting: computing content-addressable hashes of generated code and storing them alongside provenance metadata. If a regeneration produces different output from the same inputs, the fingerprint mismatch triggers investigation. This also enables SLSA-compliant provenance attestations that auditors and downstream consumers can verify.
Third, environment sealing: locking the complete execution environment — model endpoint, SDK version, dependency resolution, and infrastructure state — so that pipeline runs are reproducible. This mirrors the principle behind container image pinning but extends it to the AI generation layer. A sealed environment guarantees that re-running the pipeline against the same commit produces the same validation results.
Implementing the Transition: A Practical Roadmap
Migrating from a traditional CI/CD pipeline to an AI-aware architecture does not require a wholesale replacement. Teams can adopt these capabilities incrementally, layering new gates onto existing infrastructure.
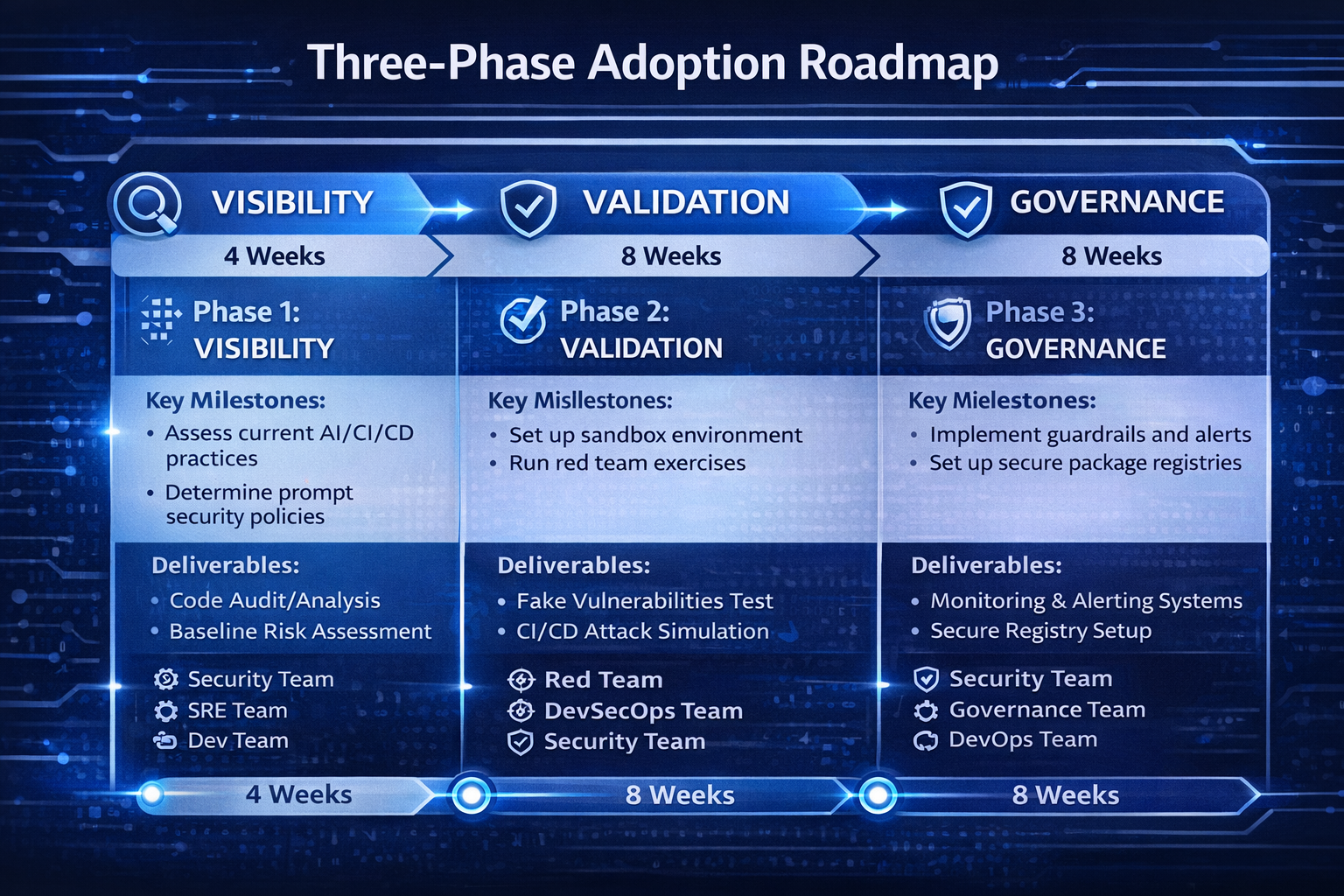
Phase 1: Visibility (Weeks 1–4)
- Instrument provenance tagging. Modify commit hooks or agent frameworks to attach origin metadata to every commit. Start with a simple human/AI binary classification and iterate toward richer metadata.
- Audit dependency reality. Add a pre-build step that verifies every new dependency against public registries. Flag any package with zero download history or registration dates within 90 days.
- Baseline AI code volume. Measure the percentage of your codebase and weekly commits that originate from AI agents. Without this baseline, you cannot size validation infrastructure.
Phase 2: Validation (Weeks 5–12)
- Deploy AI-tuned security scanning. Layer AI-specific rule sets onto your existing SAST tools. Focus on the top five LLM anti-patterns: hardcoded secrets, injection-prone queries, insecure deserialization, permissive CORS, and broken authentication flows.
- Introduce specification-aware tests. For critical business logic, write property-based tests derived from product specifications rather than implementation details. These tests validate what the code should do, not how it does it.
- Implement differential testing. Where AI-generated code replaces existing implementations, run both versions in parallel and compare outputs. Discrepancies trigger manual review.
Phase 3: Governance (Weeks 13–20)
- Generate AI-BOMs automatically. Integrate AI-BOM generation into the pipeline so every release ships with a machine-readable manifest of AI-generated components, model versions, and generation contexts.
- Enforce regulatory compliance gates. Map your organization's regulatory obligations to automated pipeline checks. EU AI Act, SOC 2, and industry-specific frameworks each impose different requirements on AI-generated artifacts.
- Establish reproducibility infrastructure. Implement generation pinning and artifact fingerprinting for all AI-generated code paths. Set up sealed environments for critical pipeline stages.
The Organizational Dimension: Who Owns the AI Pipeline?
Technical architecture alone is insufficient. AI-aware pipelines introduce new ownership questions that organizations must resolve. Traditional CI/CD ownership sits with platform engineering or DevOps teams. AI-generated code validation, however, spans security (for anti-pattern detection), legal (for IP and licensing compliance), product (for specification-aware testing), and ML engineering (for model provenance).
Leading organizations are creating cross-functional AI governance boards that define pipeline policies, with platform engineering responsible for implementation. 63% of breached organizations in 2025 lacked AI governance policies entirely, and shadow AI usage — agents deployed without pipeline integration — added an average of $670,000 to breach costs. The pipeline is the enforcement mechanism, but the policies it enforces must come from a broader coalition.
This also requires rethinking developer education. When AI writes the code, the human developer's role shifts from author to reviewer, auditor, and specification writer. The skill of 2026 is not writing code faster but reading AI-generated code critically — spotting the subtle logic inversions, the plausible-but-wrong architectural decisions, and the dependencies that shouldn't exist.
Conclusion
The CI/CD pipeline is no longer just a deployment mechanism — it is the primary quality and security boundary between AI-generated code and production systems. Organizations that continue relying on pipelines designed for human-speed, human-scale development are accumulating risk with every AI-generated commit that bypasses meaningful validation.
The architecture outlined here — provenance tracking, AI-specific compliance gates, and deterministic reproducibility — is not speculative. The tools exist, the standards are maturing, and the regulatory pressure is real. The question is not whether your pipeline needs to become AI-aware, but whether it will happen by design or by incident response.








