

Enterprise AI has an 80% failure rate reaching production, and the models are not the problem. For three years, organizations poured resources into Retrieval-Augmented Generation pipelines, convinced that connecting a language model to a vector database would unlock enterprise intelligence. Most of those projects never shipped.
Now, even the term's co-creator acknowledges the shift. Douwe Kiela, lead author of the original 2020 RAG paper, recently conceded:
"I think people have rebranded it now as context engineering, which includes MCP and RAG."
That admission is more than a branding exercise. It signals a fundamental architectural rethinking—one that GCC teams building AI-powered enterprise systems cannot afford to ignore.
This article unpacks why traditional RAG stalls in production, defines context engineering as the broader discipline replacing it, and maps a practical architecture for enterprise teams ready to build systems that actually work.
Why 80% of Enterprise RAG Projects Never Ship
The pattern is familiar: a proof-of-concept demo impresses leadership, but the production deployment never arrives. According to industry analysis, 72% of enterprise RAG implementations either fail outright or deliver significantly below expectations in their first year. The root causes cluster around three structural weaknesses.
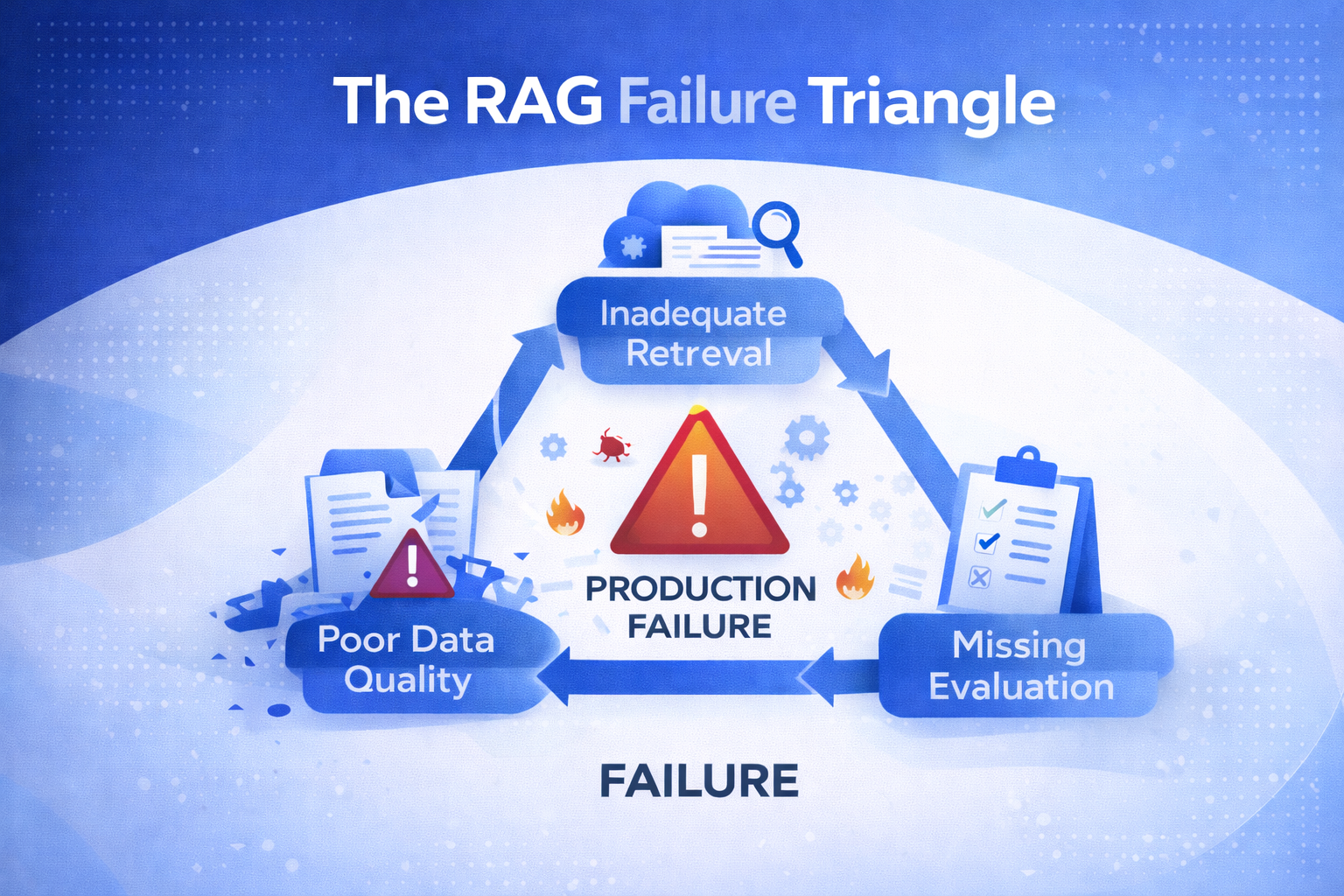
Poor Data Quality
RAG pipelines assume that chunked documents contain the right information in the right format. In practice, enterprise knowledge bases are riddled with stale policies, contradictory versions, and unstructured data that resists meaningful chunking. The retrieval layer faithfully surfaces garbage, and the model confidently presents it as fact.
Inadequate Retrieval
Basic semantic search—the default in most RAG implementations—returns contextually similar documents, not necessarily the most relevant ones. A query about "Q4 revenue policy" might retrieve a two-year-old memo instead of the current fiscal guideline. Without query decomposition, re-ranking, and hybrid search strategies, retrieval accuracy degrades rapidly in large corpora.
No Evaluation Framework
Perhaps the most damaging gap is measurement. Research (Gao et al., 2024) shows that over 70% of LLM application errors stem from incomplete or poorly structured context, not from model capability. Yet most teams lack systematic ways to evaluate retrieval relevance, answer faithfulness, or context sufficiency—flying blind through production.
From RAG to Context Engineering: More Than a Rebrand
Context engineering is the discipline of designing systems that dynamically assemble the right information for an AI model at the right time. Where RAG focuses narrowly on document retrieval, context engineering encompasses the entire information supply chain: what data is retrieved, how it is structured, what tools are available, what the system remembers, and how all of these are orchestrated per task.
Gartner has declared 2026 "the year of context," predicting that context will become the fundamental architectural layer in enterprise AI. This is not a prediction about models getting smarter; it is a recognition that the bottleneck has shifted from the model side to the context side.
Think of it this way: RAG is to context engineering what a carburetor is to a modern engine management system. The carburetor mixes fuel and air—retrieval mixes documents and queries. But a modern engine manages fuel injection, ignition timing, emissions, and turbo boost as an integrated system. Context engineering is an integrated system for AI.
The Four Pillars of Context Engineering
A production-grade context engineering architecture rests on four interdependent layers, each addressing a failure mode that standalone RAG cannot handle. These components must work as a coordinated system, not as isolated add-ons.
Knowledge Retrieval Layer
This layer evolves RAG from a single-pass lookup into an agent-controlled retrieval loop where the system decides its own search strategy, reformulates queries when results are insufficient, and iterates until confident. It combines dense vector search with keyword matching, knowledge graphs, and learned re-rankers.
Memory Management Layer
Enterprise workflows span hours, days, and quarters. A context-engineered system maintains three tiers of memory: ephemeral turn context for the current interaction, session-level context for multi-step tasks, and persistent long-term memory capturing user preferences and institutional knowledge. This eliminates the amnesia that plagues stateless RAG.
Tool Integration via MCP
The Model Context Protocol, introduced by Anthropic in 2024, standardizes how AI systems connect to external tools, databases, and APIs. As Kiela noted, if you use MCP to do your retrieval, it is essentially RAG—but MCP extends far beyond retrieval into calculations, transactions, and cross-system orchestration.
Context Orchestration Layer
The orchestration layer is the conductor that decides what information is injected, in what order, and in what format. It routes queries to the appropriate retrieval source, manages context window budgets, and ensures the model receives a coherent, prioritized input rather than a raw dump of documents.

A Practical Architecture for GCC Enterprise Teams
For GCC teams building AI-powered enterprise systems, the transition from RAG to context engineering is not optional—it is the difference between demo-ware and production value. McKinsey research on AI adoption in GCC countries confirms that implementation success depends on cross-functional teams combining data engineering, domain expertise, and robust orchestration infrastructure.
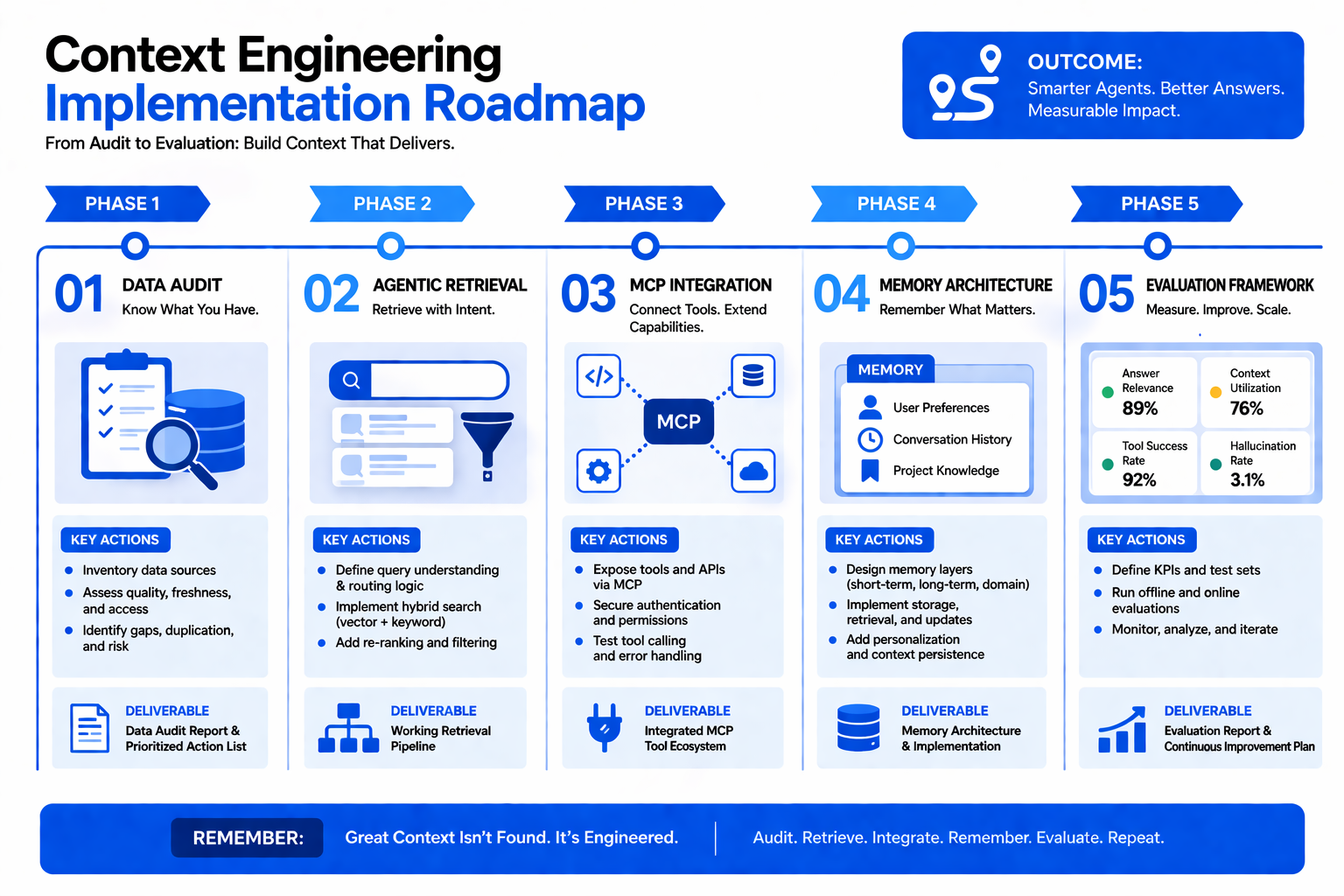
Here is how to map the four-pillar architecture to a practical implementation:
- Start with data foundations, not models. Audit your enterprise knowledge bases for currency, consistency, and coverage before building retrieval pipelines. Context engineering demands clean, well-structured data as its raw material.
- Implement agentic retrieval from day one. Skip basic vector search. Deploy query decomposition, hybrid search combining semantic and keyword matching, and re-ranking stages. Build evaluation harnesses that measure retrieval precision against ground-truth answers.
- Adopt MCP for tool standardization. Rather than hardcoding API integrations, use MCP to create a consistent interface layer. This future-proofs your architecture as new tools and data sources come online.
- Design memory hierarchies for your workflows. Map your business processes to determine which context needs to persist across sessions, which is user-specific, and which represents institutional knowledge. Build memory tiers accordingly.
- Build evaluation into the pipeline. Instrument every stage—retrieval relevance, context sufficiency, answer faithfulness—with automated metrics. What you cannot measure, you cannot improve.
Gartner predicts that 40% of enterprise applications will feature task-specific AI agents by late 2026, up from less than 5% in 2025. Every one of those agents will require robust context engineering. Teams that build the architectural foundations now will capture disproportionate value as adoption accelerates.
Conclusion
RAG is not dead in the sense that retrieval disappears—it is dead as a standalone architecture. Context engineering absorbs retrieval into a broader system that includes memory, tools, and orchestration, addressing the structural failures that kept 80% of enterprise RAG projects from reaching production. For GCC teams, this shift demands investing in data quality, agentic retrieval, MCP-based tool integration, and rigorous evaluation frameworks.
The organizations that thrive will be those that treat context as an engineering discipline, not an afterthought. If your team is ready to move beyond RAG and architect production-grade AI systems, Crewscale specializes in building the cross-functional teams and infrastructure that make context engineering work at enterprise scale.








