

Imagine a product manager spinning up a governed revenue dashboard in an afternoon—without filing a ticket, copying data, or waiting a quarter for engineering. That scenario is no longer speculative. AI-assisted development has matured from hobbyist experimentation into a credible way to ship production software. According to McKinsey, generative AI can help developers complete coding tasks up to 45% faster, collapsing timelines that used to drag on for weeks.
The missing piece in enterprise settings has always been data. Production tables, machine-learning models, and sensitive records live behind access controls for good reason, and earlier generations of AI coding tools treated those controls as friction to route around. The recently announced Replit and Databricks integration flips that assumption: the AI builds against governed sources directly, not copies of them.
This article walks through what vibe coding actually is, why the enterprise data layer stalled its early adoption, how the Replit and Databricks workflow now resolves that friction, and what business teams can realistically build on top of it.
What Is Vibe Coding and Why It's Going Enterprise
Vibe coding refers to the practice of building software primarily by describing what you want in natural language and letting an AI agent scaffold the structure, logic, and connections. The term captures a workflow shift: developers are no longer writing every line; they curate intent, review generated code, and iterate conversationally.
Adoption has been rapid. 76% of developers are using or planning to use AI coding tools, up sharply from prior years. The advantages compound: faster scaffolding, fewer boilerplate tasks, and a lower barrier for non-specialists to contribute to real application code.
From Prototypes To Production
Early vibe coding flourished in hackathons and weekend projects. Moving it into the enterprise required three upgrades: reliability of generated code, integration with existing systems, and—most importantly—respect for organizational controls like access management, audit logging, and data residency.
Why Enterprises Are Taking It Seriously
Gartner has long predicted that the majority of new business applications would be built outside traditional IT, driven by the rise of citizen development and low-code platforms. Vibe coding accelerates that trend by replacing drag-and-drop builders with fluent natural-language interfaces. The result: product managers, analysts, and operations leaders can author real software, not just dashboards and forms.
The Enterprise Data Challenge
Every serious business application needs data—usually live, trusted data. That is where most vibe coding projects used to hit a wall.
Sales pipelines, support histories, financial ledgers, and customer records sit in data warehouses managed by platform teams. Those teams enforce access controls, audit trails, and compliance rules for valid reasons: a single leaked table can trigger regulatory penalties or competitive harm. When a business builder needed that data for a prototype, the options were poor. Copying data to a personal environment violated governance. Filing a request meant joining the multi-quarter engineering backlog.
The cost is real. IDC estimates that global data volume is expanding by double-digit percentages annually, yet a large share of that data remains inaccessible to the teams who could extract value from it. The gap between "data that exists" and "data that business teams can actually act on" has become one of the most consequential inefficiencies in modern enterprises.
How the Replit and Databricks Integration Works
The integration resolves the governance bottleneck by letting applications query Databricks directly, inheriting the same permissions, audits, and policies the platform already enforces. Nothing is copied. Nothing escapes the governed boundary.
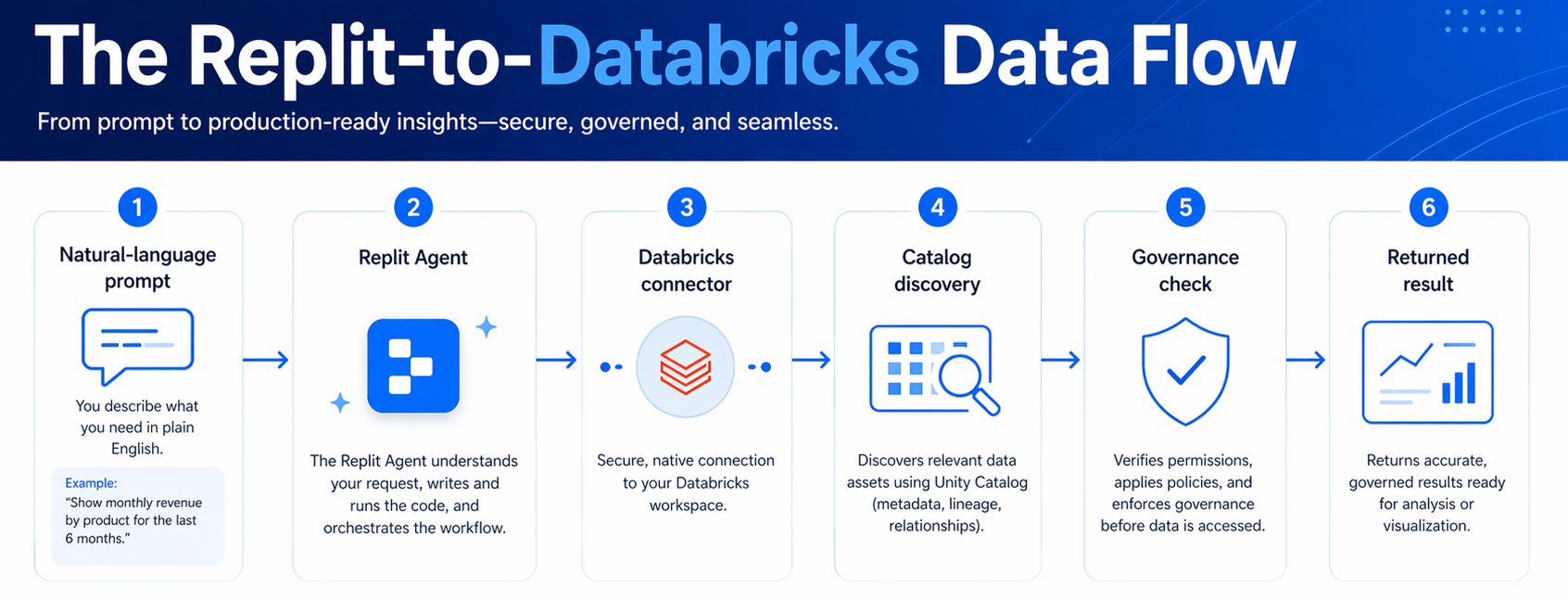
The Workflow In 4 Steps
- Add the Databricks connector inside the Replit IDE. A single configuration exposes the integration to the Replit Agent.
- Authenticate against the Databricks workspace using existing identity and role assignments.
- Discover data assets automatically. The agent surfaces accessible catalogs, schemas, tables, models, and vector indexes.
- Build and iterate. Generated code queries the discovered sources natively, with access control checks enforced at the Databricks layer.
Traditional vs. Vibe-Coded Development
Genie as a Data Copilot
Databricks Genie layers on top of the integration as a natural-language interface to the catalog itself. Before a builder even types a prompt in Replit, Genie can help identify which tables and fields are relevant and cite exact column lineage. That pairing—Genie for data discovery, Replit for app scaffolding—creates a coherent path from question to working application, with provenance preserved at every step.
AppKit Templates for Production-Ready Apps
Starting from a blank file is rarely the fastest way to build a governed enterprise app. Databricks AppKit provides a TypeScript framework with opinionated defaults, built-in observability, and plugin-based extensions to Databricks services like SQL warehouses, model-serving endpoints, and Lakebase.
Inside Replit, builders can start from an AppKit-based template, collaborate live with teammates on the same canvas, and let the Replit Agent scaffold code that conforms to AppKit conventions. When the application is ready, it deploys into Databricks Apps, where it inherits the same governance, security, and operational telemetry expected of any production workload.
The combination closes the loop. The builder never leaves the governed environment. The data never leaves the governed environment. The application never leaves the governed environment. What moves fast is the creation, not the risk surface.
Real Use Cases for Business Builders
The point of this integration is not hypothetical. Several categories of application become trivial to build:
- Revenue operations dashboards that query live pipeline data and surface anomalies without waiting for the next BI sprint.
- Customer success workflows that join support ticket histories with product usage signals to triage accounts.
- Financial planning tools that model scenarios against real general ledger tables, refreshing in near real time.
- Internal search experiences built on top of vector indexes and model endpoints, the data team already curates.
- Visual prototypes and demos, such as the 3D weather globe showcased in the launch livestream, which assembled an interactive front end and a governed data pipeline within minutes.
Who Actually Builds These
Product managers sketching experiments, analysts publishing live reports, RevOps teams automating territory planning, marketers instrumenting campaigns with real-time segments—anyone whose work is gated by data access. Organizations treating trusted data as a shared, broadly accessible asset consistently outperform peers on decision velocity.
Business Impact and Guardrails
Vibe coding over governed data is not a loophole; it is a new division of labor.
What Data Teams Gain
Platform engineers reclaim time previously spent on one-off requests. Because every generated application queries through the same governance layer, the surface area for shadow IT shrinks, and compliance posture improves rather than degrades.
What Business Builders Gain
Time to first working version collapses from quarters to afternoons. Iteration stays conversational—edit the prompt, regenerate, redeploy—rather than batched into monthly release trains.
The deeper shift is cultural. When governance and speed stop being in tension, organizations can redesign their software supply chain around real-time collaboration between data, engineering, and business teams.
Conclusion
Vibe coding has matured. By wiring Replit's AI-powered agent directly into Databricks' governed data plane, the most common barrier to building real business applications—trusted access to real data—disappears. The result is faster iteration, durable compliance, and a meaningful expansion in who gets to author software inside the enterprise.
Start small: pick one recurring data request that sits in your engineering backlog and prototype it as a Replit app backed by a Databricks connector this week. For teams ready to institutionalize the pattern across functions, Crewscale partners with Beanbag AI to design governance, templates, and skill-up strategies so vibe coding scales safely from pilot to platform.








